This post will explain about configuring a three node kubernetes cluster in CentOS machine.
Before you begin i will give you a basic idea about what we are going to achieve here.
Kubernetes is an open source container management system that will help us to deploy containers and scale them according to our requirement.If you need to create a 2 node cluster with some applications we can configure that with the help of kubernetes. Kubernetes master will take care of all the resource allocation and maintenance of the containers deployed in the cluster.
In this tutorial i am setting up a two node cluster using three CentOS machines. Please not you need to have root access to complete the steps described and you need to run till step 8 in all the nodes.
Step 1: Identify the ip address and Host name of the machines that we are going to configure
10.1.X.X -- Machine host name 1 -- > Kubernetes Master
10.1.X.X -- Machine host name 2 -- > Kubernetes Slave Node 1
10.1.X.X -- Machine host name 3 -- > Kubernetes Slave Node 2
Step 2: Edit /etc/hosts file in all the three machines and add the three ip address
Eg:
10.1.x.x Host_name_1
10.1.x.x Host_name_2
10.1.x.x Host_name_3
Step 3: Do a yum update
#sudo
yum update
Step 4: Do some other configurations in the machine
using the below commands
sudo setenforce
0
sudo sed -i
--follow-symlinks 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/sysconfig/selinux
sudo modprobe
br_netfilter
sudo echo '1'
> /proc/sys/net/bridge/bridge-nf-call-iptables
sudo swapoff –a
sudo vim
/etc/fstab
in fstab check are you able to see the UUID
then exit from the editor
Step 5: Install Docker
sudo yum install -y yum-utils
device-mapper-persistent-data lvm2
sudo yum install -y docker-ce
Step 6: Install Kubernetes
Add the kubernetes repository
to the centos system by running the following command.
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg
EOF
Now install the kubernetes
packages kubeadm, kubelet, and kubectl using the yum command below.
sudo yum install -y
kubelet kubeadm kubectl
Step 7: Reboot the machine
#sudo reboot
Step 8: Start Docker and Kubernetes
systemctl start docker && systemctl enable docker
systemctl start kubelet && systemctl enable kubelet
We need to make sure the
docker-ce and kubernetes are using same 'cgroup'.
Check docker cgroup using the
docker info command.
docker info | grep -i cgroup
And you see the docker is using
'cgroupfs' as a cgroup-driver.
Now run the command below to
change the kuberetes cgroup-driver to 'cgroupfs'.
sed -i 's/cgroup-driver=systemd/cgroup-driver=cgroupfs/g'
/etc/systemd/system/kubelet.service.d/10-kubeadm.conf
Reload the systemd system and
restart the kubelet service.
systemctl daemon-reload
systemctl restart kubelet
Now we're ready to configure
the Kubernetes Cluster.
Step 9: Kubernetes cluster initialization.
In this step, we will
initialize the kubernetes master cluster configuration.
Move the shell to the master
server 'k8s-master' and run the command below to set up the kubernetes master.
kubeadm
init --apiserver-advertise-address=10.1.X.X --pod-network-cidr=10.244.0.0/16
Note:
--apiserver-advertise-address =
determines which IP address Kubernetes should advertise its API server on(Master server).
--pod-network-cidr =
specify the range of IP addresses for the pod network. We're using the
'flannel' virtual network. If you want to use another pod network such as
weave-net or calico, change the range IP address.When the Kubernetes
initialization is complete, you will get the result as below.
As shown in the command window you can use the kubeadm join command to join nodes to the cluster. Save this join token number for future use. If you need to add one more node to the existing cluster you can run this command on the salve node and join that node with the master.
Step 10:
Now in order to use Kubernetes,
we need to run some commands as on the result.
Create new '.kube'
configuration directory and copy the configuration 'admin.conf'.
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Next, deploy the flannel
network to the kubernetes cluster using the kubectl command.
The flannel network has been
deployed to the Kubernetes cluster.
Wait for a minute and then
check kubernetes node and pods using commands below.
Step 11:
Run the below commands to see the status of the cluster with nodes and the running pods in the container.
kubectl get nodes
kubectl get pods --all-namespaces
And you will get the
'k8s-master' node is running as a 'master' cluster with status 'ready', and you
will get all pods that are needed for the cluster, including the
'kube-flannel-ds' for network pod configuration.
Make sure all kube-system pods
status is 'running'.
Kubernetes cluster master
initialization and configuration has been completed.
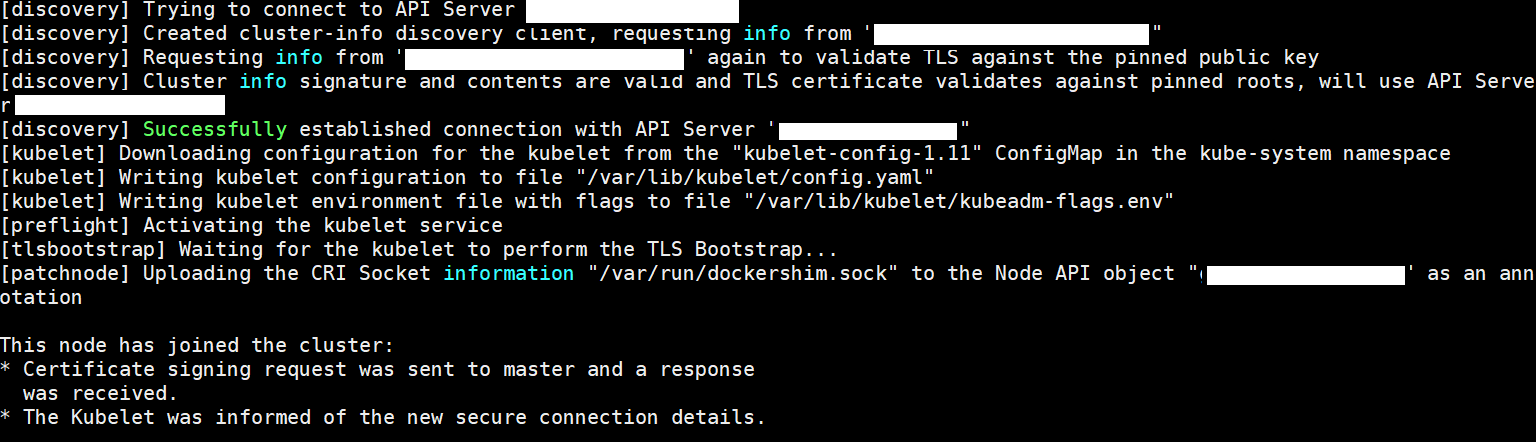
Step 12: Adding nodes to the existing cluster.
You can use the join command that you received when initializing the cluster to add nodes to the cluster. open shell script in each slave nodes and run the join command so as shown below you can see the node are joined to your cluster.
Wait for some minutes, and back
to the master cluster server check the nodes using the following
command.
sudo kubectl get nodes
Now you can see the cluster is ready with one master and two slaves. From the status bar we can see the status as Ready.

























{kind=link}